Систематические и случайные ошибки измерений
Систематическая ошибка - ошибка исследования, не связанная с выборкой. Она может быть вызвана концептуальными или логическими ошибками, неправильной интерпретацией ответов, а также статистическими, арифметическими, табуляционными, кодовыми или отчетными ошибками.Систематические ошибки подразделяется на: случайные(дают оценки, отличные от истинного значения; они могут приводить к отклонениям и в большую, и в меньшую сторону и имеют при этом случайный характер) и неслучайные(приводят к односторонним отклонениям, для них характерна тенденция к смещению выборочного значения относительно параметра совокупности). Недостатки систематических ошибок: - не так часты, но и не настолько подконтрольны, как ошибки в выборке;- в систематических ошибках, как направление, так и величина ошибки могут оказаться совершенно непредсказуемыми, в отличие от выборок, где ошибки в выборке при использовании вероятностных методов могут быть оценены; - приводят к смещению выборочного значения относительно параметра совокупности;- влияют на достоверность выборочных оценок. Особенно критичными ошибки становятся при работе с широкомасштабными, хорошо продуманными вероятностными выборками, т.к. при увеличении эффективности проектирования выборки и уменьшении выборочной дисперсии, эффект систематических ошибок усиливается. Чем эффективнее составлена выборка, тем большую роль играют систематические ошибки и тем меньшим смыслом обладают вычисления по определению доверительного интервала, в основе которых лежат обычные формулы. Систематические ошибки делятся на два основных типа: ошибки, связанные с неполучением данных (ошибки ненаблюдения), и ошибки наблюдения. Ошибки ненаблюдения возникают вследствие невозможности получения данных от части элементов обследуемой совокупности и быть вызваны тем, что часть обследуемой совокупности не была представлена в выборке, или же элементы, отобранные для включения в выборку, не представили данных. Ошибки наблюдений возникают вследствие некорректной информации, полученной от элементов выборки, они могут возникнуть и на стадии обработки данных или формулирования итогового вывода.
48.Понятие и сущность ошибок ненаблюдения. Существуют два типа ошибок ненаблюдения: ошибки неохвата( систематическая ошибка, являющаяся следствием того, что определенные части или целые блоки генеральной совокупности не были включены в основу выборки) и ошибки неполучения данных. Неохват может стать источником серьезных неточностей, при этом ошибка неохвата относится только к ошибочно выпавшим из рассмотрения частям совокупности. Таким образом, проблема неохвата имеет отношение к основе выборки.Ошибка перебора может возникать из-за возникновения повторов в сводке элементов выборки.Ошибки неохвата:1) относятся к разряду систематических ошибок и потому не входят в стандартные стат. зависимос. ;2) как правило, не могут быть устранены посредством увеличения объема выборки;3) могут иметь существенный размер;4) могут быть уменьшены при осознании их наличия с помощью улучшения основы выборки и принятия ряда специальных мер, позволяющих до определенной степени компенсировать остаточное несовершенство основы. Ошибка неполучения данных – систематическая ошибка, порождаемая отсутствием информации о некоторых элементах, которые должны были войти в состав выборки. Для того, чтобы оптимизировать и стандартизировать практику исследований предлагается определение доли ответивших(отношение количества проведенных с респондентами интервью к количеству приемлемых респондентов в выборке). Различают две главные причины ошибки неполучения данных - это отсутствие и отказ от интервью. Отсутствие – систематическая ошибка, возник. вследствие неполучения ответов от заранее определенных респондентов, отсутствующих дома в момент звонка регистратора.Отказы от интервью – систематическая ошибка, возникающая вследствие того, что часть респондентов отказывается принимать участие в обследовании. Доля отказов зависит часто от особенностей респондентов, организаций, осуществляющих финансовое обеспечение обследования, обстоятельств контакта, темы обследования и искусства интервьюера.Стратегии, рекоменд. для корректировки ошибки:1. Увеличение доли первичных ответов (улучшение условий проведения интервью и углубленное обучение интервьюеров).2. Повторные попытки.3. Экстраполяция получ.информации(оценка возможного эффекта, обусловленного неполучением данных, и соответствующая коррекция результатов исследования).Частичное неполучение данных состоит в том, что респондент, согласившийся принять участие в опросе, не хочет или не может ответить на некоторые вопросы из-за специфики их формы или содерж. или вследствие нежелания обременять себя поиском инф.
49.Понятие и сущность ошибок наблюдения
Ошибка сбора – систематическая ошибка, возникающая при сборе данных.Человек отказ отвечать на одни и дает неправильные ответы на другие вопросы интервьюера - ошибками пропуска и ошибками свидетельства. Поведенческие факторы . Биографические данные, мнения, позиции, намерения респондента могут являться источниками ошибок. Существуют 3 модели поведения интервьюеров , которые приводят к появлению ошибок: ошибки при формулировке вопросов и неумение задавать уточняющие вопросы, ошибки при записи ответов, подтасовка данных.Достоверность:
1) Метод опроса - проверяется соответствие использованного метода заданному (например, действительно ли проводился персональный, а не телефонный опрос).
2) Поставленные вопросы - проверка того, не были ли выпущены из рассмотрения важные вопросы (демографического или классификационного характера).
3) Демонстрация продукции - проверка того, действительно ли была произведена потребная для проведения опроса демонстрация продукта или информационного листа.
4) Знакомство респондента с интервьюером - проверка того, не занимался ли интервьюер опросом своих знакомых или друзей.
5) Реакция на проведение опроса - проверка «качества» работы интервьюера.
Офисные ошибки . Систематические ошибки могут возникать не только при сборе информации. Они могут появляться при редактировании, кодировании, составлении таблиц и анализе данных.
Суммарные ошибки. Частные ошибки, складываясь, приводят к ошибке суммарной, которая и должна интересовать исследователей.
При работе с ошибками сбора данных можно воспользоваться схемой Кана- Кэннела
интервьюер респондент
Характеристики: Характеристики: теже что и у интер-ра
Возраст Психологические факторы:теже
Образование Поведенческие факторы:
Ответы на вопросы
(адекватные – неадекватные)
(точные – неточные)
Социально-экономический статус
Национальность,Религиозная принадлежность,Пол и т.д.
Психологические факторы: Восприятие,Позиция,Намерения,мотивы
Поведенческие факторы: Ошибки при вопросах,Ошибки при распределении типа респондентаОшибки мотивации,Ошибки при записи ответов
Личные особенности (характеристики). личные особенности могут серьезно повлиять на ответы. Психологические факторы . результаты работы интервьюеров имеют обусловленность их взглядами, позициями и стремлениями.
50.Редактирование данных. Редактирование включает в себя просмотр и, если необходимо, исправление каждой анкеты или формы регистрации наблюдений. Просмотр и внесение исправлений выполняются в 2 стадии: полевое редактирование и централизованное офисное редактирование.
Полевое редактирование - это предварительное редактирование, которое строится таким образом, чтобы обнаружить наиболее бросающиеся в глаза пропуски и неточности данных.
Оно также полезно для контроля поведения персонала полевых сил и внесения ясности. Полевое редактирование выполняется как можно скорее после того, как анкета заполнена. В этом случае проблемы могут быть устранены прежде, чем проводивший сбор информации будет расформирован. Полевое редактирование обычно выполняется руководителем полевых работ.
Централизованное офисное редактирование - всеобъемлющая проверка и коррекция заполненных форм сбора данных, включая принятие решения о том, что с этими данными делать.
Чтобы обеспечить логическую последовательность обработки материалов, лучше всего предоставить все носители собранных данных одному человеку. Если эту работу приходится делить по соображениям ее объема и имеющегося времени, подразделы должны определяться по частям анкеты, а не по респондентам. То есть, один редактор должен редактировать часть «А» всех анкет, а другой - часть «В».
В отличие от полевого, централизованное офисное редактирование в меньшей степенизависит от последующих процедур, и в большей - от степени полноты данных. При анализе необходимо решить, каким образом будут обрабатываться носители собранных данных, содержащие неполные ответы, явно неправильные ответы и ответы.
Вернувшиеся заполненные анкеты целиков. В некоторых окажутся пропущенными целые разделы. Другие будут оставленными без ответа отдельные позиции. Анкеты, в которых пропущены целые разделы, не должны отбрасываться автоматически. Тщательное редактирование анкеты иногда показывает, что ответ на какой-то вопрос очевидно неправилен.
При анализе необходимо не пропустить заполненные анкеты, которые неудачны с точки зрения интереса респондента. Свидетельства отсутствия интереса могут быть и очевидными, и очень трудно распознаваемыми.
51. Кодирование данных. Код-е – технический прием, с помощью которого данные распределяются по категориям. Прием связан со спецификацией альтернативных категорий или классов, в которые должны помещаться ответы, а самим классам должны назначаться кодовые номера.
I этап код-я заключается в специфицировании категорий или классов, к которым будут относиться ответы. Выбор ответов должен быть взаимоисключающим и исчерпывающим, чтобы каждый ответ логически попадал в одну категорию. Код-е закрытых вопросов и большинства средств балльной оценки не сложно; потому что оно устанавливается при конструировании самой анкеты. Код-е открытых вопросов более сложно и более дорогое, т.к. приходится определять подходящие категории на базе ответов, которые не всегда предсказуемы. Если анкет слишком много, и необходимо использовать для кодирования анкет нескольких кодировщиков, дополнительной проблемой может стать возникновение несоответствия в самом кодировании. Поэтому для получения логической последовательности обработки данных, эту работу необходимо разделять по задачам, а не в равных долях делить анкеты между кодировщиками.
II этап код-я касается назначения кодовых номеров классов. Принято, для обозначения классов использовать цифры, а не буквы. Когда для анализа данных предполагается использовать компьютер, кодирование необходимо выполнять таким образом, чтобы данные оказывались готовыми для ввода в машину, поэтому полезно обеспечить наглядность ввода посредством многоколонной записи. Когда вопрос допускает множество ответов, допускать отдельные колонки для кодирования каждого варианта ответа.
Необходимо использовать ровно столько колонок поля, назначаемого для переменной, сколько необходимо для полного охвата всех ее возможных значений. Кроме того, любому полю должна назначаться не более чем одна переменная.Рекомендуется применять стандартные коды для «отсутствия информации». Так, все ответы «не знаю» должны кодироваться цифрой 8, «нет ответов» - цифрой 9, а «не применялось» обозначаться как 0. Лучше, если во всем исследовании для каждого из этих типов «нет информации» используется один и тот же код.
Завершающий этап код-я состоит в подготовке книги кодов , которая содержит общие инструкции, указывающие, каким образом была закодирована каждая позиция данных. В ней перечисляются коды каждой переменной и категории, включенные в каждый код.
52.Табулирование данных. Табулирование заключается просто в подсчете количества событий, которые попадают в различные категории. Табулирование может принимать форму простой табуляции, или перекрестной табуляции . Простая табуляция - подсчет количества событий, которые попадают в каждую категорию, когда категории базируются на одной переменной.Перекрестная табуляция - подсчет количества событий, которые попадают в каждую из нескольких категорий, когда категории базируются на двух и более переменных, рассматриваемых одновременно.Одномерная табуляция используется в следующих целях:
1. для определения степени безответности позиций анкеты является важной проблемой в большинстве исследований. Когда степень безответности большая, исследование в целом становится сомнительным и возникает необходимость пересмотреть его цели и методы. Возможно использование нескольких стратегий. - Оставить позиции пустыми и описать их количество как отдельную категорию. -Исключать событие с утраченной позицией при анализе с использованием соответствующей переменной. -Подставить значения утраченных позиций анкеты. 2. для локализации грубых ошибок . Грубая ошибка– ошибка, которая возникает при редактировании, кодировании, клавиатурном наборе или табулировании данных.3. для локализации посторонних значений- наблюдение, настолько отличающееся по величине от остальных наблюдений, что возникает необходимость обрабатывать его как особое значение.4. для определения эмпирического распределения рассматриваемой переменной. Лучше всего представить в виде гистограммы.5. для расчета итоговых статистик.
Перекрестная табуляция является важным механизмом для изучения связей внутри и между переменными. В перекрестной табуляции выборка делится на подгруппы. Связь между двумя переменными в пределах категорий размера семьи, называется условной таблицей , позволяющей обнаружить условную связь между переменными.Условные таблицы, построенные на основе одной регулируемой переменной, называются условными таблицами первого порядка . Таблицы, составленные с использованием двух регулируемых переменных, называются условными таблицами второго порядка .В настоящее время табулированные результаты чаще представляются в виде баннеров. Баннер – это последовательныйряд перекрестных табуляций между критерием и несколькими факторными переменными, оформленный в виде единой таблицы.
53.Традиционный, классический метод анализа документов и его составляющая.Традиционный анализ – это цепочка умственных, логических построений, направленных на выявление сути анализируемого материала с определенной, интересующей исследователя точки зрения в каждом конкретном случае. Основным недостатком этого анализа является субъективность. В традиционном анализе различают внешний и внутренний анализ. Внешний анализ – это анализ контекста документа и тех обстоятельств, которые сопутствовали его появлению. Цель внешнего анализа – установить вид документа, его форму, время и место появления, автора и инициатора, какие цели преследовались при его составлении, степень надежности и достоверности, каков его контекст. Внутренний анализ – это исследование содержание документа. Отдельные виды документов из-за своей специфики, требуют специальных методов анализа и привлечения для их выполнения специалистов других областей знаний. Юридический анализ. Он применяется для всех видов юридических документов. Его специфика заключается в том, что разработан особый словарь терминов, в котором значение каждого слова строго однозначно определено.Психологический анализ. Он применяется при оценке отношения автора к какому-либо политическому, экономическому или социальному явлению. На основе таких исследований можно получить представление о формировании общественного мнения, общественных установок и т.д.
54. Формализованный, количественный (контект-анализ) и его состав-е . Его называют часто количественный метод анализа документов (контент-анализ).Суть этих методов сводится к тому, чтобы найти легко подсчитываемые признаки, черты, свойства документа, которые отражали бы определенные существенные стороны содержания. Тогда качественное содержание делается измеримым, становится доступным для точных вычислений.Контент-анализ – это техника выделения заключения проводимого с помощью объективного и систематического выявления соответствующих характеристик текста задачам исследования. Существуют общие принципы, когда применяется контент-анализ:1. Когда требуется высокая степень точности или объективности анализа.2. При наличии большого по объему и несистематизированного материала.3. Когда категории, важные для целей исследования, характеризуются определенной частотой появления в изучаемых документах.Основными направлениями использования контент-анализа являются:
1. Выявление и оценка характеристик текста как индикаторов определенных сторон изучаемого объекта;2. Выявление причин, породивших сообщение; 3. Оценка эффекта воздействия сообщения (например, рекламного).Требование объективности анализа предполагает решение ряда проблем, связанных:1. с выработкой категорий анализа. Категории анализа – это понятие, в соответствии с которыми будут сортироваться единицы. Требования, предъявляемые к категориям:- должны быть исчерпывающими, - взаимоисключаемыми, - надежность.2.С выделение единиц анализа. Единицей анализа (смысловой или качественной) является та часть содержания, которая выделяется как элемент, подводимый под ту или иную категорию. Индикаторами могут быть:- относящиеся к теме слова и словосочетания;- термины;- имена людей;- названия организаций;- географические названия;- пути решения экономических проблем, 3. с выделение единиц счета. Единицы счета обладают разной степенью точности измерения, а так же разным временем, уходящим на кодировку материала, попавшего в выборку. В практике методом контент-анализа были выделены общие единицы счета, отвечающие различным исследовательским требованиям.1.Время – пространство. 2.Появление признаков в тексте
3.Частота появления. При разработке программы маркетинговых исследований необходимо четко определить, какого рода характеристики объекта подвергаются изучению, и в зависимости от этого оценивать документы с точки зрения их адекватности, надежности, достоверности.
Адекватность документа определяется как степень, в которой он отражает интересующие исследователя характеристики объекта.
Надежность оценивается сопоставлением всех данных содержания с какими-то другими данными. Здесь возможны несколько вариантов проверки:
1.Сравнение содержания документов , исходящих из одного источника. Такое сравнение может проводиться:а) во времени б) в различных ситуациях
в) в различных аудиториях .2.Метод независимых источников , т.е. выбираются характеристики из нескольких различных источников информации. Затем различия в характеристиках сравниваются с различиями в содержании сообщений.Оценка достоверности данных документа проводится путем последовательного перебора источников встречающихся в документе ошибок. Источники ошибок можно разделить на две категории:
Случайные (например, опечатки в статистических данных) -систематические.
Систематические ошибки делятся на сознательные и несознательные
Сознательные ошибки часто определяются теми намерениями, которыми руководствуется автор при составлении документа.
?
План:
1. Введение
3. Случайные и систематические ошибки
4. Ошибок теория
5. Вмешивающиеся факторы
6. Методы контроля над систематическими ошибками
7. Заключение
8. Литература
1. Введение
Систематическая ошибка
Систематической ошибкой (СО, смещением, bias, англ.) называют смещение среднего результата измерения по отношению к истинной величине. Например, из-за особенностей применяемых реагентов разные способы измерения концентрации отдельных веществ в крови (например, тропонина или глюкозы) дают несколько различные результаты.
Всякое отклонение выводов от истины или процесс, приводящий к подобному отклонению, называют СО. Так же обозначают любое уклонение (искажение) в сборе, анализе, интерпретации, публикации или обзоре данных, ведущее к выводам, которые систематически отличаются от истины. Основные механизмы возникновения смещений следующие.
1. Систематическое (одностороннее) отклонение результатов измерений от истинных величин (СО в узком смысле, «СО измерения»).
2. Отклонение суммарных статистических оценок (средних, частот, мер связи и т.д.) от их истинных значений в результате систематического отклонения результатов измерений, других погрешностей в сборе данных или погрешностей в дизайне исследования, анализе данных.
3. Отклонения выводов от истины в связи с недостатками дизайна исследования, сбора данных, анализа или интерпретации результатов.
4. Тенденция процедур (в дизайне исследования, при сборе данных, анализе, интерпретации, обзоре или публикации результатов) давать результаты или выводы, отклоняющиеся от истины.
5. Предубеждения, заставляющие сознательно или неосознанно выбирать такие процедуры исследования, которые ведут к отклонению от истины в определенном направлении или к односторонней интерпретации результатов.
Исследователи стремятся получать в исследованиях несмещенные оценки, но это не всегда возможно, и в таком случае исследователь должен оценивать возможную величину смещения. Термин СО (смещение) не обязательно предполагает обвинения в предубежденности или наличии другого субъективного фактора, такого как желание получить определенный результат. Смещённая оценка может быть лишь следствием несовершенства дизайна исследования или какого-то его элемента.
2. Разновидности систематических ошибок
Описано множество разновидностей СО. Приводимый ниже список неполон. Он предназначен для того, чтобы проиллюстрировать разнообразие на примерах наиболее изученных и распространенных СО. Назвать какие-то СО более важными нельзя, потому, что появление в исследовании любой из них может приводить к серьезным последствиям, таким как обнаружение преимущества нового метода лечения перед старым или, наоборот, невозможность выявить важное преимущество одного способа лечения или диагностики перед другим.
Незнание возможных СО может приводить к ошибкам (или подталкивать к умышленному использованию этих СО), а потому СО надо учиться распознавать даже тем, кто не собирается проводить исследования. Умышленные или неумышленные смещения в оценках методов диагностики и лечения - основная причина, по которой некоторые бесполезные методы считаются полезными, а полезные методы не используются, поскольку оцениваются как бесполезные или вредные.
Ошибки выборки
СО выборки (sampling bias) - СО, возникающая в результате изучения неслучайной выборки. Ее не следует путать с ошибкой выборки (sampling error), которая является частью общей ошибки оценки параметра, возникающей из-за случайного характера выборки. Ошибка выборки случайна, она возникает как проявление того, что каждая случайная выборка из популяции отличается (вариабельность выборочных результатов, sampling variation).
Ошибка обращаемости (ascertainment bias) - СО, связанная с включением в исследуемую выборку лиц или случаев, не представляющих равным образом все классы (подгруппы) популяции. Причины этой СО разнообразны. Это может быть особенность источника, откуда поступают обследуемые лица, например, поликлиника завода (в результате выборка не будет отражать состояние здоровья населения). Это может быть способ выявления людей, их особенностей, в частности диагнозов, на который могут влиять обычаи и культура.
СО отбора (selection bias) - ошибка, вызванная систематическими различиями характеристик у тех, кто принимает участие в исследовании и теми, кто в нем не участвует. Такая ошибка возникает в исследовании, в которое включают только добровольцев (они отличны от тех, кто не пожелал участвовать) или только госпитализированных пациентов, находящихся под наблюдением врача (исключены те, кто умер до госпитализации из-за тяжелого течения заболевания, и те, кто еще недостаточно болен для того, чтобы нуждаться в госпитализации, и те, кто из-за стоимости лечения или расстояния не был госпитализирован). В результате СО отбора могут возникать ложные связи и замаскировываться реально существующие. СО отбора - очень частая проблема, многообразная в своих проявлениях.
СО отклика (response bias) - СО, вызванная различиями в характеристиках тех, кто добровольно вызвался принять участие в исследовании, и тех, кто отказался.
СО вследствие выбывания из исследования (bias due to withdrawals) - СО, возникающая вследствие различия между величинами истинными и величинами, полученными в исследовании, в результате особенных характеристик участников, вышедших из исследования. Например, при изучении катамнеза не удается найти часть больных. Изучение характеристик только тех, кого удалось найти, может давать искаженное представление даже о таких показателях, как смертность.
СО серии вскрытий (bias in autopsy series) - СО в оценке патологоанатомической картины, возникающая в результате того, что вскрытые умершие являются нерандомизированной выборкой из всех смертных случаев. Например, при анализе текущих результатов патологоанатомических вскрытий нельзя не учитывать, что патологоанатомы изучают только половину умерших. Возможно, что в «невидимой» половине и структура причин смерти, и частота расхождений с клиническим диагнозом иные.
СО распределения пациентов (allocation bias) - в экспериментальных исследованиях методов лечения возможно неравное распределение пациентов между сравниваемыми группами, в результате, например, сравнивается частота или скорость выздоровления у «легких» больных, получающих новое вмешательство, с аналогичными признаками у более тяжелых б ольных, получающих стандартное лечение.
Ошибки измерения
СО инструментального измерения (bias due to instrumental error) - СО, возникающая вследствие недостатка измерительного прибора, дефектов его калибровки, использования недоброкачественных реактивов, неправильных технологий измерения и т.д.
Феномен предпочтения чисел (digit preference) - предпочтение определенных чисел, обычно приводящее к округлению измерений. Округление может производиться до ближайшего целого числа, дробного числа, кратного 5 или 10, а при других единицах измерения - соответственно им, например, при измерении неделями - 7, 14 дней, при оценке интенсивности курения – до 20 (пачки, Рис. 2) и т.д. Предпочтение чисел может быть свойством лица, отвечающего на вопросы в обследовании, или формой ошибки наблюдателя. Например, курильщики на вопрос о количестве выкуриваемых сигарет бессознательно округляют до 5, так же поступают обычно врачи, регистрируя результаты измерения артериального давления.
Рис. 2. Распределение курильщиков (ордината, %) по числу выкуриваемых в день сигарет. Данные любезно предоставлены Я. Балабановой.
СО представления данных (bias in the presentation of data) - ошибка в результате неоднородностей, вызванных предпочтением чисел, неполнотой данных, некачественными лабораторными процессами, плохими методами измерения.
СО информации (information bias, син.: observational bias - СО наблюдения) - в результате погрешностей в процедуре наблюдения или оценки в сравниваемых группах могут возникать разные ошибки, и, соответственно, может возникнуть (или быть скрыто) различие между группами или зависимость.
СО интервьюера (interviewer bias) - СО, возникающая, когда человек, проводящий опрос, подсознательно или сознательно избирательно регистрирует неполную или искаженную информацию. Это может быть следствием того, что интервьюер не владеет языком опрашиваемых, имеет предрассудки, а также иными причинами.
СО наблюдателя (observer bias) - систематическое различие истинных значений и наблюдаемых результатов, из-за ошибки наблюдателя. Человек не только использует инструменты, но и сам в жизни и в исследовании выступает как инструмент в оценке времени, определении момента возникновения явления, наличия явления (например, тени, осадка, кристаллов). В этом качестве человек дает результаты, в которых обязательно присутствует случайная ошибка. Последнюю называют ошибкой наблюдателя (observer variation, observer error). Наличие ошибки наблюдателя часто недооценивается. Между тем, общее правило гласит, что все наблюдения подвержены вариациям, и всегда следует ожидать, что будут иметься расхождения между повторными наблюдениями одного исследователя и расхождения между исследователями.
Вариации можно уменьшить, но полностью их избежать невозможно. Причины ошибок наблюдателя бесконечны. Исследователь может не заметить отклонение или думать, что обнаруженного не существует; измерение или тест могут дать неверные результаты из-за ошибочного метода или неверного прочтения и записи данных; исследователь может неверно интерпретировать образ или наблюдение. Выделяют две разновидности ошибки наблюдателя: вариации результатов исследователей (interobserver variation, т.е., различия результатов измерений разными исследователями) и вариация результатов одного исследователя (intraobserver variation, т.е. различия результатов в серии измерений одного и того же объекта, проделанной одним исследователем).
Всю совокупность ошибок наблюдателя (случайную и систематическую ошибки) можно в значительной степени устранить, если измерения проводить параллельно и независимо двумя или более исследователями. Поскольку ошибки исследователей в основном независимы, то расхождения измерений (оценок) укажут на такие ошибки. Эти ошибки станет возможным устранить, для чего существуют разные методы, из которых простейший - вычисление средней оценки. Возможно возникновение специфической СО наблюдателя (или СО измерения) в оценке методов лечения. Если при тяжелом заболевании испытывается новый способ лечения в открытом эксперименте, пациенты, получающие новое (дорогое или недоступное другим) вмешательство, могут выше оценивать результаты лечения в сравнении с пациентами контрольной группы, получающими стандартное вмешательство.
СО памяти (recall bias) - СО, возникающая вследствие различия в точности или полноте воспоминаний о прошлых событиях или жизненном опыте. Например, больной человек лучше, чем здоровый, может вспомнить события, потенциально связанные с возникновением заболевания.
СО сообщения информации пациентом (reporting bias) - СО вследствие выборочного сообщения или сокрытия информации о прошлой истории болезни, например, о деталях половой жизни. Обычно эта СО проявляется в сокрытии общественно осуждаемых форм поведения и может возникать не только при изучении пациентов, людей в популяции, но и при изучении поведения врачей.
СО в обращении с выпадающими величинами (bias in the handling outliers) - СО, возникающая вследствие включением в анализ необычных (выпадающих из общего ряда) значений в маленькой выборке или же вследствие исключения из анализа необычных значений, которые следовало включить.
Ошибки дизайна и анализа
СО опережения (lead time bias, син. zero time shift - сдвиг точки отсчета). Обычным в медицинской практике является стремление к выявлению заболевания ранее обычного (интервал опережения, lead time), например, до возникновения симптомов. Предполагается, что лечение в этом случае будет более успешным, и это увеличит выживание. Если выживание измеряется временем от выявления болезни до смерти, то ранняя диагностика может создавать иллюзию увеличения выживания за счет того, что болезнь будет просто выявляться раньше, т.е. возникает переоценка времени выживания из-за сдвига назад точки отсчета выживания (Рис. 3). Для надежного выявления истинного характера увеличения длительности выживания после диагностики необходимы сравнительные экспериментальные исследования. В более общем случае СО опережения возникает, когда наблюдения за группами пациентов начинаются на несравниваемых стадиях естественного развития заболевания. Например, вмешательства у женщин, страдающих раком молочной железы, который выявляется путем скрининга, нельзя сравнивать с вмешательствами у женщин, болезнь которых выявляется клиническим осмотром при обращении на более поздней стадии болезни.
Рис. 3. Происхождение СО опережения. При обычной диагностике заболевание, возникшее в 1998 г., выявляется в 2005 г. и приводит к смерти в 2007 г. При ранней диагностике заболевание будет выявлено в 2002 г. (интервал опережения 3 года). При сохранении той же продолжительности жизни период выживания после выявления болезни увеличивается на 2 года за счет сокращения периода жизни «без диагноза».
СО продолжительности (length bias) - СО, возникающая при изучении болезни на выборке преваленсных случаев (всех случаев, найденных в популяции или в регистре. В такой выборке оказываются преимущественно представлены длительно текущие случаи. СО продолжительности может возникать не только в поперечном исследовании, но и в когортном по ретроспективно собранным данным, в исследовании типа сравнения с контролем и других.
Рис. 4. Возникновение СО продолжительности. при изучении преваленсных случаев. В любой момент Т времени Х однократное обследование популяции выявит преимущественно длительно текущие случаи заболевания (длинные линии), а короткие пропускаются.
СО дизайна (design bias) - различие между истинной величиной, например, величиной эффекта ЛС, и величиной, полученной в результате неправильного дизайна исследования. Например, в неконтролируемом исследовании терапевтического эффекта ЛС может быть невозможно отличить влияние на исход болезни ЛС и более высокого дохода у тех, кто мог оплатить это ЛС. В некоторых случаях, применительно к отдельным особенностям дизайна их влияние на оценку исхода известно (это называют «эффект дизайна»). Например, если требуется изучить влияние правил ведения больных врачом на исходы, то не совсем правильно предложить врачу вести больных разными способами (опытную группу - так, а контрольную - иначе). При этом все больные неизбежно начинают получать некое «усредненное» лечение.
Правильнее рандомизировать врачей, и тогда больные одного врача будут получать одно лечение, а больные другого - другое. Это называется кластерным дизайном. При кластерном дизайне выявляемый эффект (разница в исходах при двух вмешательствах) больше, но для достижения статистической значимости эффекта необходимо больше пациентов, чем было бы необходимо при обычном дизайне (параллельном, простая случайная выборка) и равной величине эффекта. Это отличие в результатах исследования, зависящее от особенностей дизайна, называют эффектом дизайна. Отдельные дизайны более, чем другие, подвержены ВВФ. Так, в исследованиях сравнения с контролем и обсервационных исследованиях ВВФ больше и спектр возможных смещений шире, чем в экспериментальных исследованиях типа двойных слепых контролируемых испытаний. СО дизайна не следует путать с подверженностью отдельных дизайнов разным систематическим ошибкам. Например, описания серии случаев и исследования типа сравнения с контролем, сравнения с историческим контролем и с географическим (внешним) контролем подвержены широкой гамме СО. В сравнении с этими дизайнами проспективные контролируемые испытания, в особенности рандомизированные слепые испытания, лучше защищены от возникновения СО, поскольку в этот дизайн встроены несколько механизмов защиты от возможных СО.
Ошибка Берксона (Berkson"s bias, Berkson"s fallacy) - разновидность СО отбора, которая возникает из-за того, что в исследовании типа случай-контроль исследуемые и контрольные лица систематически отличаются друг от друга. Например, так происходит случаях, когда изучаемая экспозиция (воздействие) повышает риск госпитализации при данной болезни, а не риск болезни. Это систематически приводит к повышению частоты экспозиции у госпитализированных больных по сравнению с пациентами контрольной группы, также находящимися в стационаре; в свою очередь, это увеличивает отношение шансов. Например, если у летчиков обнаружение изменений позвоночника приводит к обязательной госпитализации, а у других авиационных специалистов - обычно к амбулаторному обследованию, тогда сравнение летчиков в стационаре с другими пациентами выявит связь профессии с изменениями позвоночника.
СО выявления (detection bias) - СО в результате систематической погрешности в методах выявления, диагностики или верификации случаев в исследовании. Например, больные, отобранные для исследования в первичной практике, отличаются от отобранных в больнице, поскольку в последней доступны специальные лабораторные тесты. Вариант: СО спектра патологии . При исследовании нового диагностического теста его точность в выявлении патологии может выглядеть высокой. В действительности это успешное выявление больных, например, раком простаты, может быть связано с тем, что контрольную группу составляли студенты-медики, а группу больных - больные с диагнозом, верифицированным на операции. Как только метод будет применен в группе пожилых мужчин для выявления относительно ранних случаев рака, может оказаться, что его возможности в выявлении больных невелики.
СО диагностической проработки (workup bias) - СО, вызванная неверным или неполным выявлением случаев, более частым в одной группе исследования. Обычно это происходит потому, что пациенты с положительным результатом первого теста, используемого вначале, получают более тщательное обследование при дальнейшей диагностике, чем те пациенты, у которых результат первого теста был отрицательным. При сопоставлении заболеваемости в профессиональных группах эти группы могут иметь различный доступ к диагностическим технологиям.
СО предположения (bias in the assumption, cин. conceptual bias - концептуальная ошибка) - ошибка в результате неверной логики. Ложные выводы об объяснениях ассоциации между переменными. Неоднократно документировано, как исследователь переносит на новый объект концепции, оказавшиеся плодотворными в предыдущем исследовании.
СО интерпретации (bias of interpretation) - СО в выводе и толковании. Возникает вследствие ограниченной возможности исследователя рассмотреть все возможные интерпретации, соответствующие фактам, и оценить достоинства каждого из них или вследствие пренебрежение случаями, которые представляют собой исключения из общего вывода.
Феномен регрессии к средней,который проявляется во всех продольных исследованиях. Вследствие действия случайных факторов аналитического происхождения и вследствие временных изменений в состоянии людей (например, легкое инфекционое заболевание), получаемые при измерении величины могут быть завышены, занижены, или соответствовать долговременным (постоянным) индивидуальным особенностям. Происхождение регрессии к средней следующее. Если величина, измеренная в первый раз, не была существенно смещена вследствие аналитических или внутрииндивидуальных вариаций, то при следующем изменении она изменится непредсказуемо, в среднем для таких субъектов не изменится никак. Если же величина была завышена, то она в следующий раз будет примерно средней, т.е. приблизится к средней относительно первого значения. Чем более она была завышена (например, вследствие большой аналитической ошибки), тем больше она сдвинется к средней, типичной для популяции величине. В случаях, где наблюдалась заниженная вследствие аналитических и внутрииндивидуальных колебаний величина, тоже будет сдвиг к средней - повышение. Если бы имели место только аналитические вариации, то регрессия к средней полностью реализовывалась бы при втором измерении. Поскольку внутрииндивидуальные вариации могут быть долгосрочными, постольку возврат к средней, например, после болезни или после изменения образа жизни в связи со сменой работы, может занимать месяцы и годы.
Экологическая ошибка (ecological fallacy). Для выявления связи экспозиции и заболевания можно сопоставлять экспозицию у отдельных людей с возникновением у них болезней, а можно сопоставлять экспозицию популяций (стран) с заболеваемостью в этих странах. Исследования второго типа называют экологическими. На основании связи между национальным потреблением соли и распространенностью язвенной болезни желудка и двенадцатиперстной кишки в большом числе стран можно предположить наличие между этими явлениями причинной связи. Можно далее сделать выводы относительно необходимых мер профилактики. Это было бы типичной экологической ошибкой - перенесением на возникновение болезней у отдельных людей закономерностей, полученных в экологических исследованиях. Множество связей, найденных в экологических исследованиях, не были подтверждены на индивидуальном уровне. Противоположная ошибка - перенос на уровень популяции закономерностей, изученных на отдельных людях (атомистическая СО).
Ошибки в обнародовании результатов исследований
Специалисты и публика, использующие медицинскую и иную научную литературу, склонны рассматривать ее как совокупность относительно объективных научных сообщений, которые в большей или меньшей степени точно отвечают на поставленные вопросы. Это расхожее представление соответствует предположению о том, что научные статьи могут содержать ошибочную информацию с элементом случайной ошибки. В действительности истина, открывающаяся в научных исследованиях, отражается в публикациях не только со случайно ошибкой, но и с рядом СО. Эти ошибки в совокупности называют СО обнародования (по-английски используется термин reporting bias, который относится также к ошибке сообщения информации пациентом). В целом СО обнародования создают медицинским научным журналам специфический облик витрины непрекращающихся сообщений об успехах в диагностике и лечении.
Главная из ошибок обнародования - публикационная СО (publication bias) . В основном она состоит в том, что не все результаты исследований публикуются (обнародуются). Публикуются чаще те исследования, которые принесли положительные результаты, т.е., в выгодном свете представляют новое лечение. Эта проблема не только медицинских исследований, она характерна для всей человеческой деятельности (см. видеоиллюстрацию из Monty Python’s на YouTube: http://www.youtube.com/watch? v=7l_jkRQ4vJs). СО обнародования присуща не только результатам экспериментальных исследований, но и всех других. Везде, где есть хоть какой-то стимул для разного отношения исследователя или спонсора к разным результатам исследования, возникают систематические ошибки. Исследователь работает, в той или иной мере отдавая предпочтение рабочей гипотезе. Если она не подтверждается, то это ведет к разочарованию, потере интереса к опубликованию. Опубликование статьи - это трудный процесс, и нужно хотеть, чтобы оно состоялось. Неопубликование данных исследования - не просто нарушение принципов научного поиска. Это может быть опасным. Так, в 80-х годах ХХ века группа авторов исследовали антиаритмическое ЛС. В группе пациентов, которые его получали, обнаружилась высокая летальность. Авторы расценили это как случайность, и, поскольку разработка этого антиаритмического ЛС была прекращена, то публиковать материалы не стали. Позднее подобное антиаритмическое ЛС - флекаинид - стало причиной гибели множества людей.
Система, в которой работает исследователь, может подталкивать к обнародованию только положительных результатов. Например, русская диссертационная система не принимает «отрицательных» результатов. В 2004 г. МЖМП опубликовал призыв сообщить о прецеденте защиты диссертации с отрицательным выводом по основному положению, но, несмотря на обещание премии, так ни одного сообщения и не получил. Но самый важный фактор, определяющий отказ от обнародования - интересы спонсора. Классический пример - отказ от опубликования результатов фармацевтическими компаниями в случае, когда исследование приносит отрицательный результат. Наоборот, положительный результат, хорошо отражающийся на продажах, может многократно повторно публиковаться. Этот механизм, конечно же, характерен не только для фармацевтических компаний. Производители оборудования ведут себя таким же образом. Производители табака точно так же финансируют исследования и публикуют избирательно то, что им выгодно. СО обнародования не относится только к контролируемым испытаниям. Она присутствует в исследованиях всех дизайнов.
Для отдельно взятого читателя, знакомящегося с отдельно взятой статьей или несколькими статьями, наличие публикационной СО незаметно, как незаметны микроорганизмы на коже. Трудно представить, что статья, на чтение которой ты нашел время, оказалась перед твоими глазами не потому, что она важна, а потому, что спонсор потратил средства на ее повторное опубликование, на напечатание отдельных оттисков, раздаваемых на конференции бесплатно, на гонорар профессору, который эту статью упомянул в лекции. Именно поэтому на первом месте у врача должен быть поиск защищенной от СО информации, прежде всего - систематических обзоров. Точно так же у исследователя на первом месте должна быть не работа с «образцом» какого-то предшествующего исследования, а работа с совокупностью предшествующих данных. Поэтому каждый исследователь на этапе планирования работы должен выполнить систематический обзор предшествующих исследований по изучаемому вопросу.
Помимо основного фактора - результата исследования - на вероятность опубликования влияют и иные факторы.
Языковое смещение. По понятным причинам исследования, исходящие из англоязычных стран Запада, легче находят путь на страницы ведущих международных англоязычных журналов. С этой СО тесно связана СО финансирования - исследования, имеющие существенное финансирование, публикуются чаще, чем исследования инициативные, не финансируемые извне. Здесь имеет значение не только фактор обязательств исследователя перед спонсором, но и ограниченность собственных средств исследователя. Последний может найти время для инициативного исследования, но, получив «отрицательный» результат, не найти более времени для того, чтобы трудиться над его опубликованием. Близка к языковой и «СО развивающихся стран» - известная трудность для исследователей из развивающихся стран опубликоваться в международных журналах. Интересно, что в основе этой СО лежит недоверие редакторов к исследованиям из развивающихся стран. Это не мешает периодической публикации в лучших журналах одиозных фальсифицированных исследований из этих стран или плагиата.
Сами авторы оказывают влияние на то, какие исследования, будучи обнародованными, присутствуют в обороте. Например, статья из провинциального русского журнала, будучи процитированной в другой статье, опубликованной в международном журнале, включается в научный оборот. Если этого не произойдет, то статьи из журнала, не индексируемого в международных базах данных, останутся вне мирового научного оборота.
Исследователь, выполняющий систематический обзор, также может внести СО в его результаты. Поэтому систематические обзоры также должны оцениваться читателями критически. Прежде всего, такая ошибка возникает за счет манипулирования критериями включения и исключения исследований из обзора. Этим широко пользуются сегодня производители ЛС, оборудования, предметов ухода для того, чтобы с помощью систематического обзора показать преимущество своего продукта. Самый известный пример - спонсирование производителями альбумина обзора с результатами, отличающимися от обзора, показавшего неэффективность инфузий альбумина при тяжелой травме.
СО отсрочки публикации. Все исследования, имеющие меньшие шансы на опубликование, одновременно еще и позднее публикуются. В целом, чем менее «поразителен» результат, чем меньше он нужен спонсору и самому исследователю, тем позднее он публикуется. Для инициативных исследований отсрочка в опубликовании может составлять многие годы.
СО сообщаемого исхода (outcome variable selection bias). В зависимости от интересов исследователя и по иным причинам в опубликованных отчетах могут фигурировать в первую очередь те изученные признаки, которые наиболее привлекательны, лучше приемлемы для «передового» журнала, или лучше подтверждают интересы спонсора. Например, в медицине вполне обычно опубликование результатов исследования с позитивной оценкой некоего вмешательства на основании только измерения толщины интимы артерии или изменения концентрации отдельных липопротеидов, в то время, как клинически важные исходы могут не сообщаться, сообщаться не полностью, или сообщаться в более поздних публикациях. Обычно это связано с тем, что в значительной части исследований удается обнаружить «интересные» изменения в биохимических параметрах, но не в смертности, качестве жизни, инвалидности больных.
Случайные и систематические ошибки
Полученные при непосредственном измерении величины неизбежно содержат ошибки, обусловленные самыми разными причинами. Среди этих ошибок следует различать систематические и случайные.
Систематические ошибки обусловливаются причинами, действующими вполне определённым образом. Примером систематической ошибки при взвешивании может являться смещение стрелки ненагруженных весов относительно нулевой отметки на некоторую постоянную величину?m. Зная это смещение (например, взвесив гирю, масса которой точно известна), можно, всякий раз измеряя массу на этих весах, вычитать?m из показаний прибора. Таким образом, систематические ошибки могут быть устранены или достаточно точно учтены.
Случайные ошибки вызываются большим числом отдельных причин, действующих в каждом отдельном измерении различными способами. В примере со взвешиванием это могут быть незаметные глазу колебания чаши весов, потоки воздуха, толчки фундамента здания, в котором стоят весы. Эти ошибки полностью исключить невозможно.
Полная ошибка измерения принимается равной сумме случайной и систематической ошибок: ? = ?сл + ?сист.
Пример 1
Определите, какие ошибки из перечисленных являются случайными:
1) ошибка при однократном измерении сопротивления проводника;
2) отклонение значения сопротивления проводника от измеренного более точным прибором в процессе измерения сопротивления одного и того же проводника 100 раз в одну и ту же сторону;
3) однократное измерение диаметра сосуда;
4) отклонение значения внутреннего диаметра одного и того же сосуда при измерении 30 раз в разные стороны.
Показать решение
Случайная ошибка, возникающая при измерении некоторой величины, может теоретически принимать любые значения. Она является непрерывной случайной величиной, подчинённой определённому закону распределения вероятности.
Наиболее часто встречающиеся на практике ошибки распределены по нормальному закону:
При этом, как уже было вычислено,
С какой вероятностью измеренная величина будет отклоняться от своего точного значения не больше, чем на?? Очевидно с той же самой, с которой ошибка измерения будет находиться в промежутке [–?; ?]. Если случайная ошибка распределена по нормальному закону, то для ответа на этот вопрос необходимо вычислить интеграл
Расчёты показывают, что в 68,27 % отклонения случайной величи
и т.д.................
Систематическая ошибка -- это систематическое (неслучайное, однонаправленное) отклонение результатов исследований от истинных значений. Выделяют несколько основных видов систематических ошибок.
Систематическая ошибка, обусловленная нарушением правил подбора пациентов (selection bias). Она чаще всего возникает на этапе формирования исследуемых групп в результате отбора для включения в исследование лиц, которые не являются репрезентативными для общей совокупности больных. Эта систематическая ошибка создаётся в результате того, что сравниваемые группы испытуемых различаются не только по основным признакам, но и по другим факторам, влияющим на результат исследования, т.е. участники фактически отбираются из разных популяций.
Пример: в том случае, когда в качестве группы контроля используются ранее набранные больные, а методика их обследования с течением времени претерпела изменения, наступает хронологическое смещение.
Пример: в исследование включаются добровольцы, сами откликнувшиеся на объявление об исследовании.
Систематическая ошибка отбора может приводить в ИСК к формированию контрольной группы, плохо сопоставимой с основной группой. Например, при формировании контрольной группы из больных с другим заболеванием вмешиваются привходящие факторы, связанные с этой болезнью. С другой стороны, если контрольная группа формируется из общей популяции, то результаты могут оказаться несопоставимыми с основной группой, например, по возрасту и полу. Для предотвращения этой ошибки нужно подбирать пациентов попарно в контрольную и основную группы по нескольким признакам, потенциально влияющим на изучаемые показатели. Другой вариант предотвратить ошибку - использовать несколько контрольных групп.
Ошибка подбора, более характерная для ИСК, может возникать и в РКИ, если, например, из контрольной группы теряются самые тяжелые пациенты.
Систематическая ошибка, возникающая при измерении, вследствие неудачно выбранного метода оценки результатов исследования. Подобная ошибка появляется тогда, когда пациенты в сравниваемых группах обследуются неодинаково (разные методы диагностики, частота обследований) или используются нестандартизованные схемы получения данных и субъективные оценки.
Субъективная оценка в большинстве случаев даёт завышенный результат по сравнению с оценкой независимого эксперта и/или объективными методами.
Пример: ошибка вследствие различия в степени подробности сбора анамнеза в группах больных и здоровых.
Пример: рентгенологи, если проводят оценку рентгенограмм, зная дополнительную информацию о пациенте, могут более пристально и критически оценивать «контрольных» пациентов, по сравнению с «получающими активное лечение».
Систематическая ошибка, обусловленная действием вмешивающихся факторов (confounding), проявляется тогда, когда изучаемые факторы взаимосвязаны, и одни из них искажают эффекты других. Это может произойти из-за систематической ошибки при отборе, под действием случайности или из-за реального взаимодействия факторов, что должно учитываться при анализе результатов исследования.
Пример: при проведении исследования влияния потребления овощей на возникновение заболевания, не была учтена разная распространенность второго фактора риска (например, курения) в сравниваемых группах.
Систематическая ошибка, обусловленная эффектом плацебо . «Эффект пустышки» - систематическое улучшение состояния пациентов при имитации лечения. Если в контрольной группе проводится лечение, внешне не отличимое от активного в группе вмешательства, то разница между этими группами исключает эффект плацебо.
В ходе наблюдения за больными у них наблюдается улучшение состояния. Часть этого эффекта объясняется естественным течением болезни, часть - неспецифическим влиянием лечения (эффект плацебо), а разница между группами соответствует дополнительной пользе, приносимой активным лечением. РКИ специально планируются так, чтобы отсеять все эффекты, за исключением собственно эффекта активного лечения.
Рисунок 1. Выявление эффекта активного лечения по сравнению с плацебо
Способы устранения систематических ошибок
Наиболее частыми источниками погрешностей при проведении КИ являются ожидания исследователей и испытуемых, влияние которых можно уменьшить путём использования стандартных способов контроля с использованием: анамнез лечение плацебо
грамотного отбора испытуемых в контрольные группы;
метода «ослепления» (маскирование вмешательства);
рандомизации (со стратификацией или без неё) при формировании различных групп испытуемых;
методов статистического моделирования.
Испытания с самоконтролем - для экспериментальной и контрольной групп привлекается один объект, например, пациент в отдельные дни получает лечение, в другие - плацебо.
Перекрестное испытание - одни пациенты выбираются для экспериментальной группы, другие - для контрольной; после остановки лечения в новом периоде группа лечения становится контрольной, а контрольная - группой лечения. При обобщенном рассмотрении результатов получается, что каждый пациент был сам себе контролем.
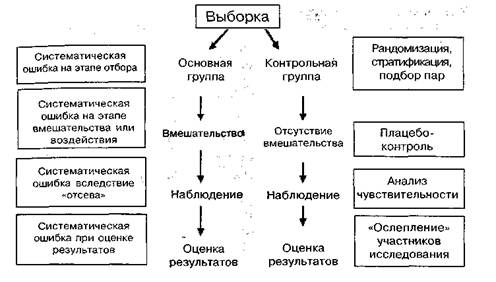
Рисунок 2. Источники систематических ошибок и методы борьбы с ними
Испытания с подобранным контролем - проводятся путём подбора контроля к каждому случаю так, чтобы они не отличались ни по одному из подозреваемых факторов. Это позволяет избежать различий между группами, связанных с известными факторами, которые не интересны в данном исследовании. Например, при изучении связи болезни с особенностями питания путем подбора контрольных лиц можно исключить влияние на здоровье дохода и курения. При подборе сравниваются различия не между всеми случаями и контролем, а совокупность различий внутри отдельных пар.
Метод маскирования вмешательств («слепое» исследование, ослепление)
Немаскируемый (открытый) метод выполнения РКИ - испытуемый и исследователь знают о лечении, которое получает испытуемый. При этом, например, испытуемый в контрольной группе может начать лечиться другими средствами и разница между группами исчезнет.
Простой слепой метод - испытуемый не знает, какое лечение он получает. Метод чреват ошибками, связанными с тем, что врач и другие медицинские работники будут относиться по-разному к ведению пациентов, получающих активное лечение и плацебо (старое и новое вмешательство).
Двойной слепой метод - исследователь и пациент не знают, какое лечение получает он или группа.
Тройной слепой метод - исследователь, пациент и руководители КИ, организующие исследование и анализирующие его результаты, не знают, какое лечение получает группа.
Рандомизация - способ распределения испытуемых в группы в случайной последовательности - с использованием таблицы случайных чисел или иного правильного метода. Рандомизация - обязательное свойство правильного проведения КИ, которое в таком случае называется рандомизированным. Использование случайных чисел гарантирует, что вероятность попадания в конкретную группу лечения одинакова для всех испытуемых. Рандомизация используется не только при проведении КИ, но и при проведении исследований на экспериментальных животных.
В настоящее время РКИ стали стандартом клинических испытаний. Разработаны разные методы рандомизации -рандомизация пациентов по группам, парная рандомизация, факторная, адаптивная и ряд других.
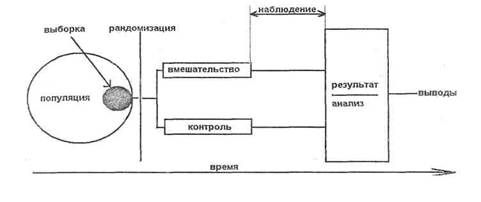
Рисунок 3. Схематическое изображение РКИ
Правильными методами рандомизации являются использование таблиц случайных чисел и компьютерных программ, а также иногда бросание монеты, т.е. методы, которые генерируют случайную последовательность распределения пациентов по группам.
Однако надо отметить, что, несмотря на всеобщее признание, суть рандомизации нередко понимают неверно и вместо случайного распределения испытуемых прибегают к упрощенным способам (по алфавиту, датам рождения, дням недели и т.д.) и даже допускают произвольное распределение в группы. Подобная «псевдорандомизация» не даёт ожидаемых результатов.
Стратификация - используется с целью обеспечения равного распределения испытуемых по группам лечения с учетом факторов, существенно влияющих на исход, например, возраста, длительности болезни и т.д. Иными словами, например, пациенты-мужчины рандомизируются независимо от женщин. Стратификация гарантирует одинаковое распределение указанных факторов в группах лечения.
Статистическое моделирование - применяется для оценки силы связи и эффекта воздействия с одновременным учётом действия множества переменных. Наиболее распространенным методом статистического моделирования вероятности качественных событий (госпитализация, смерть) является множественная логистическая регрессия.
Cтраница 1
Систематические ошибки обнаруживаются и устраняются в процессе проверки исправности машины.
Систематическая ошибка, т.е. ошибка, повторяющаяся и одинаковая во всей серии наблюдений.
Систематические ошибки вызываются причинами, действующими одинаковым образом при проведении измерений в одних и тех же условиях или закономерно изменяющих показания в какую-либо одну сторону при изменении этих условий.
Систематические ошибки возникают в том случае, если поглощающие частицы не сохраняют свою идентичность в гомогенном растворе. Обычно этот эффект включает межмолекулярную ассоциацию, особенно водородную связь и мицеллообразование.
Систематические ошибки для данного измерительного средства должны рассматриваться как случайные при общей характеристике погрешности всех измерительных средств этого типа. Например, неправильная градуировка шкалы миниметра является систематической для данного миниметра, но случайной (не постоянной по величине и знаку) для массы миниметров с такими же техническими характеристиками.
Систематические ошибки всех разновидностей суммируются алгебраически, а случайные - по вероятностным характеристикам рассеяния.
Систематические ошибки здесь отсутствуют, поэтому расчеты проводят сразу для Ас, предельных допусков и коэффициентов влияния. Заметим, что все первичные ошибки (суммарные боковые зазоры) относятся к группе п (Ср / 0, см. с.
Систематические ошибки - это ошибки, вызываемые известными причинами, или причины которых можно установить при детальном рассмотрении процедуры химического анализа. Другими словами, причины систематических ошибок значимы для аналитика.
Систематические ошибки, не изменяя величины и знака, могут повторяться во многих параллельных определениях. Например, при параллельных титрованиях нескольких проб неправильно установленным рабочим раствором получаются сходные результаты, но неверные.
Систематические ошибки обусловлены рядом причин, среди которых важнейшими являются: а) ошибки, вызванные недостаточно точным методом, б) применение рабочих растворов с неправильно установленными или изменившимися титрами, в) пользование неточными бюретками, пипетками и измерительными колбами, г) систематическое недотитрование или перетитрование, д) неправильно выбранный индикатор и е) личные особенности аналитика.
Систематические ошибки постоянны во всей серии измерений или изменяются по определенному закону. Выявление их требует специальных исследований, но как только систематические ошибки обнаружены, они могут быть легко устранены введением соответствующих поправок в результаты измерения.
Систематические ошибки часто возникают вследствие отклонения поведения реагентов или реакций, на которых основано определение, от идеального. Причинами таких отклонений могут быть малая скорость реакций, неполнота их протекания, неустойчивость каких-либо веществ, неспецифичность большинства реагентов и протекание побочных реакций, мешающих процессу определения. Например, в гравиметрическом анализе перед химиком стоит задача выделения определяемого элемента в виде возможно более чистого осадка. Если осадок не удается хорошо промыть, он будет загрязнен посторонними веществами и масса его будет завышена. С другой стороны, промывание, необходимое для удаления загрязнений, может привести к потере заметного количества осадка вследствие его растворимости; в результате возникает систематическая отрицательная ошибка. В любом случае тщательность проведения операции сводится на нет систематической ошибкой, обусловленной методом анализа.
Ошибки измерения делятся на случайные (тот самый шум, о котором шла речь ранее) и систематические. Прояснить, что такое систематическая ошибка, можно на следующем примере: предположим, мы немного изменим в схеме по рис. 13.3 сопротивление резистора R2. При этом у нас на определенную величину сдвинется вся шкала измерений: показания термометра будут соответствовать действительности, только если мы прибавим (или вычтем, неважно) некоторую константу к полученной величине: / = /’ + 5, где / - «правильное» значение температуры (оно все же отличается от истинного значения из-за наличия случайной ошибки); /’ - показания термометра; 5 - величина систематической ошибки из-за сдвига шкалы. Более сложный случай систематической погрешности - если мы оставим R2 в покое, а немного изменим R5, то есть изменим наклон характеристики термометра, или, как еще это называют, крутизну преобразования. Это равносильно тому, что мы умножаем показания на некий постоянный множитель к, и «правильное» значение будет тогда определяться по формуле: t = ht\ Эти виды ошибок носят название аддитивной и мультипликативной погрешностей.
О систематических погрешностях математическая статистика «ничего не знает», она работает только с погрешностями случайными. Единственный способ избавиться от систематических погрешностей (кроме, конечно, подбора прецизионных компонентов) - это процедуры калибровки (градуировки), о них мы уже говорили в этой главе ранее.
Случайные ошибки измерения и их оценка
я предполагаю, что читатель знаком с таким понятием, как вероятность. Если же нет - настоятельно рекомендую книгу , которая есть переиздание труда от 1946 г. Расширить кругозор вам поможет классический учебник , который отличает исключительная внятность изложения (автор его, известный математик Елена Сергеевна Вентцель, кроме научной и преподавательской деятельности, также писала художественную литературу под псевдонимом И. Грекова). Более конкретные сведения о приложении методов математической статистики к задачам метрологии и обработки экспериментальных данных, в том числе с использованием компьютера, вы можете найти, например, в . Мы же остановимся на главном - расчете случайной погрешности.
В основе математической статистики лежит понятие о нормальном распределении. Не следует думать, что это нечто заумное - вся теория вероятностей и матстатистика, как прикладная дисциплина, в особенности, основаны на здравом смысле в большей степени, чем какой-либо другой раздел математики.
Не составляет исключения и нормальный закон распределения, который наглядно можно пояснить так. Представьте себе, что вы ждете автобус на остановке. Предположим, что автопарк работает честно, и надпись на табличке «интервал 15 мин» соответствует действительности. Пусть также известно, что предыдущий автобус отправился от остановки ровно в 10:00. Вопрос - во сколько отправится следующий?
Как бы идеально ни работал автопарк, совершенно ясно, что ровно в 10:15 следующий автобус отправится вряд ли. Пусть даже автобус выехал из парка по графику, но тут же был вынужден его нарушить из-за аварии на перекрестке. Потом его задержал перебегающий дорогу школьник. Потом он простоял на остановке из-за старушки с огромной клетчатой сумкой, которая застряла в дверях. Означает ли это, что автобус всегда только опаздывает? Отнюдь, у водителя есть план, и он заинтересован в том, чтобы двигаться побыстрее, потому он может кое-где и опережать график, не гнушаясь иногда и нарушением правил движения. Поэтому событие, заключающееся в том, что автобус отправится в 10.15, имеет лишь определенную вероятность, не более.
Если поразмыслить, то станет ясно, что вероятность того, что следующий автобус отправится от остановки в определенный момент, зависит также от того, насколько точно мы определяем этот момент. Ясно, что вероятность отправления в промежутке от 10.10 до 10.20 гораздо выше, чем в промежутке от 10.14 до 10.16, а в промежутке от 10 до 11 часов оно, если не возникли какие-то форс-мажорные обстоятельства, скорее всего, произойдет наверняка. Чем точнее мы определяем момент события, тем меньше вероятность того, что оно произойдет именно в этот момент, и в пределе вероятность того, что любое событие произойдет ровно в указанный момент времени, равна нулю.
Такое кажущееся противоречие (на которое, между прочим, обращал внимание еще великий отечественный математик Колмогоров) на практике разрешается стандартным для математики способом: мы принимаем за момент события некий малый интервал времени 5/. Вероятность того, что событие произойдет в этом интервале, уже равна не нулю, а некоей конечной величине бЛ а их отношение 5P/5t при устремлении интервала времени к нулю равна для данного момента времени некоей величине /?, именуемой плотностью распределения вероятностей. Такое определение совершенно аналогично определению плотности физического тела (в самом деле, масса исчезающе малого объема тела также стремится к нулю, но отношение массы к объему конечно) и потому многие понятия математической статистики имеют названия, заимствованные из соответствующих разделов физики.
Правильно сформулированный вопрос по поводу автобуса звучал бы так: каково распределение плотности вероятностей отправления автобуса во времени? Зная эту закономерность, мы можем всегда сказать, какова вероятность того, что автобус отправится в определенный промежуток времени.
Интуитивно форму кривой распределения плотности вероятностей определить несложно. Существует ли вероятность того, что конкретный автобус отправится, к примеру, позже 10:30 или, наоборот, даже раньше предыдущего автобуса? А почему нет - подобные ситуации в реальности представить себе очень легко. Однако ясно, что такая вероятность намного меньше, чем вероятность прихода «около 10:15». Чем дальше в обе стороны мы удаляемся от этого центрального наиболее вероятного срока, тем меньше плотность вероятности, пока она не станет практически равной нулю (то, что автобус задержится на сутки - событие невероятное, скорее всего, если такое случилось, вам уже будет не до автобусов). То есть распределение плотностей вероятностей должно иметь вид некоей колоколообразной кривой.
В теории вероятностей доказывается, что при некоторых предположениях относительно вероятности конкретных исходов нашего события, эта кривая будет иметь совершенно определенный вид, который называется нормальным распределением вероятностей или распределением Гаусса. Вид кривой плотности нормального распределения и соответствующая формула показаны на рис. 13.5.
Рис. 13.5. Плотность нормального распределения вероятностей
Далее мы поясним смысл отдельных параметров в этой формуле, а пока ответим на вопрос: действительно ли реальные события, в частности, интересующие нас ошибки измерения, всегда имеют нормальное распределение? Строгого ответа на этот вопрос в общем случае нет, и вот по какой причине. Математики имеют дело с абстракциями, считая, что мы уже имеем сколь угодно большой набор отдельных реализаций события (в случае с автобусом это была бы бесконечная таблица пар значений «плотность вероятности - время»). В реальной жизни такой ряд невозможно получить не только потому, что для этого потребовалось бы бесконечно долго стоять около остановки и отмечать моменты отправления, но и потому, что стройная картина непрерывного ряда реализаций одного события (прихода конкретного автобуса) будет в конце концов нарушена совершенно не относящимися к делу вещами: маршрут могут отменить, остановку перепестри, автопарк обанкротится, не выдержав конкуренции с маршрутными такси… да мало ли что может произойти такого, что сделает бессмысленным само определение события.
Однако все же интуитивно понятно, что, пока автобус ходит, какое-то, пусть теоретическое, распределение имеется. Такой идеальный бесконечный набор реализаций данного события носит название генеральной совокупности. Именно генеральная совокупность при некоторых условиях может иметь, в частности, нормальное распределение. В реальности же мы имеем дело с выборкой из этой генеральной совокупности. Причем одна из важнейших задач, решаемых в математической статистике, состоит в том, чтобы имея на руках две разных выборки, доказать, что они принадлежат одной и той же генеральной совокупности - проще говоря, что перед нами есть реализации одного и того же события. Другая важнейшая для практики задача состоит в том, чтобы по выборке определить вид кривой распределения и ее параметры.
На свете сколько угодно случайных событий и процессов, имеющих распределение, совершенно отличное от нормального, однако считается (и доказывается с помощью т. н. центральной предельной теоремы), что в интересующей нас области ошибок измерений при большом числе измерений и истинно случайном их характере, все распределения ошибок - нормальные. Предположение о большом числе измерений не слишком жесткое - реально достаточно полутора-двух дес5Гтков измерений, чтобы все теоретические соотношения с большой степенью точности соблюдались на практике. А вот про истинную случайность ошибки каждого из измерений можно говорить с изрядной долей условности: неслучайными их может сделать одно только желание экспериментатора побыстрее закончить рабочий день. Но математика тут уже бессильна.
Полученные опытным путем характеристики распределения называются оценками параметров, и, естественно, они будут соответствовать «настоящим» значениям с некоторой долей вероятности - наша задача и состоит в том, чтобы определить интервал, в котором могут находиться отклонения оценок от «истинного» значения и соответствующую ему вероятность. Но настало время все же пояснить - что же это за параметры?
в формуле на рис. 13.5 таких параметра два- величины ц и а. Они называется моментами нормального распределения (аналогично моментам распределения масс в механике). Параметр ц называется математическим ожиданием (или моментом распределения первого порядка), а величина а - средним квадратическим отклонением. Нередко употребляют его квадрат, обозначаемый как D или просто и носящий название дисперсии (или центрального момента второго порядка).
Математическое ожидание есть абсцисса максимума кривой нормального распределения (в нашем примере с автобусом это время 10:15), а дисперсия, как видно из рис. 13.5, характеризует «размытие» кривой относительно этого максимума- чем больше дисперсия, тем положе кривая. Этим моменты имеют прозрачный физический смысл (вспомните аналогию с фи^зическим распределением плотностей): математическое ожидание есть аналогия центра масс некоего тела, а дисперсия характеризует распределение масс относительно этого центра (хотя распределение плотности материи в физическом теле далеко от нормального распределения плотности вероятности).
Оценкой гпх математического ожидания ц служит хорошо знакомое нам со школы среднее арифметическое:
Здесь п- число измерений; /- текущий номер измерения (/= l,…,w); дс/ - значение измеряемой величины в /-м случае.
Оценка дисперсии вычисляется по формуле:
![]() (2)
(2)
Оценка среднего квадратического отклонения, соответственно, будет:
Здесь (jc, – гПх) - отклонения конкретных измерений от ранее вычисленного среднего.
Следует особо обратить внимание, что сумму квадратов отклонений делить следует именно на « – 1, а не на «, как может показаться на первый взгляд, иначе оценка получится смещенной. Второе, на что следует обратить внимание - разброс относительно среднего характеризует именно среднее квадра-тическое отклонение, вычисленное по формулам (2) и (3), а не среднее арифметическое отклонение, как рекомендуют в некоторых школьных справочниках - последнее дает заниженную и смещенную оценку (не напоминает ли вам это аналогию со средним арифметическим и действующим значениями переменного напряжения?).
Заметки на полях
Кроме математического ожидания, средние значения распределения вероятностей характеризуют еще величинами, называемыми модой и медианой. В случае нормального распределения все три величины совпадают, но в других случаях они могут оказаться полезными: мода есть абсцисса наивероят-нейшего значения (то есть максимума на кривой распределения, что полностью отвечает бытовому понятию о моде), а медиана выборки есть такая точка, что половина выборки лежит левее ее, а вторая половина - правее.
В принципе этими формулами для расчета случайных погрешностей можно было бы ограничиться, если бы не один важный вопрос: оценки-то мы получили, а вот в какой степени они отвечают действительности? Правильно сформулированный вопрос будет звучать так: какова вероятность того, что среднее арифметическое отклоняется от «истинного» значения (то есть математического ожидания) не более чем на некоторою величину 8 (например, на величину оценки среднего квадратического отклонения s)?
Величина 5 носит название доверительного интервала, а соответствующая вероятность - доверительной вероятностью (или надежностью). Обычно решают задачу, противоположную сформулированной: задаются величиной надежности и вычисляют доверительный интервал 5. В технике принято задаваться величиной надежности 95%, в очень уж серьезных случаях - 99%. Простейшее правило для обычных измерений в этом случае таково: при уело-вии достаточно большого числа измерений (практически - более 15-20) доверительной вероятности в 95% соответствует доверительный интервал в 2Sy а доверительной вероятности в 99% - доверительный интервал в 3s. Это известное правило «трех сигма», согласно которому за пределы утроенного квадратического отклонения не выйдет ни один результат измерения, но на практике это слишком жесткое требование. Если мы не поленимся провести не менее полутора десятков отдельных измерений величины дс, то с чистой совестью можем записать, что результат будет равен